
با ظهور دانشنامههای هوشمصنوعیمحور مثل «گراک پدیا» (Grokipedia) پرسشهای جدی درباره کیفیت منابع، نحوه استناد و میزان بیطرفی محتوا مطرح شده است. برای هر کسبوکار، پژوهشگر یا تولیدکننده محتوا که به دادههای این پلتفرم تکیه میکند، درک عمیق منابع، استنادها و سوگیری در گراک پدیا به اندازه خود الگوریتمها اهمیت دارد. در واقع هر چه شفافیت درباره منابع، استنادها و سوگیری در گراک پدیا بیشتر باشد اعتماد ما به اطلاعات آن و استفاده از آن در استراتژی سئو و تحلیل داده منطقیتر خواهد بود.
از آنجا که «گراک پدیا» زیرمجموعه اکوسیستم هوشمصنوعی شرکت xAI است و بخش زیادی از مقالات آن با مدل «گروک» تولید میشود، بحث سوگیری الگوریتمی و انتخاب گزینشی منابع بسیار جدی است. بر خلاف ویکیپدیا (Wikipedia) که مدل مشارکتی و ویرایش جمعی دارد، در اینجا هوشمصنوعی و تیم کوچکتری از ویراستاران درباره دیده شدن یا نشدن یک منبع تصمیم میگیرند؛ موضوعی که در ادامه خواهیم دید چگونه به هسته بحث منابع، استنادها و سوگیری در گراک پدیا تبدیل میشود. برای شناخت بهتر تاریخچه و معماری این سامانه، مطالعه ((مقاله جامع گراک پدیا)) نقطه شروع مناسبی است.
نقش منابع و استنادها در ساختار دانشی گراک پدیا
برای فهم عمیقتر منابع، استنادها و سوگیری در گراک پدیا باید نگاه کنیم این دانشنامه بر پایه چه نوع دادههایی ساخته شده است. طبق توضیحات منتشرشده درباره Grokipedia، بخش زیادی از محتوا با ترکیبی از صفحات فورکشده از ویکیپدیا و متنهای تولیدشده توسط مدل زبانی «گروک» شکل میگیرد و امکان ویرایش مستقیم مقالات برای همه کاربران وجود ندارد؛ کاربران فقط میتوانند پیشنهاد اصلاح ارسال کنند تا بعد از بازبینی مدل یا تیم ویرایش اعمال شود.
در نسخههای اولیه، گزارش شده است که برخی مقالات برچسبهایی مانند «Fact Checked by Grok» دارند که نشان میدهد مدل با مراجعه مجدد به وب و چند منبع منتخب، محتوای صفحه را بازآزمایی کرده است. این طراحی در ظاهر قرار است اعتماد به منابع را تقویت کند اما نکته کلیدی برای تحلیل منابع، استنادها و سوگیری در گراک پدیا این است که خود انتخاب این منابع و نحوه وزندهی به آنها توسط الگوریتم انجام میشود نه جامعه بزرگ و متنوعی از ویراستاران.
بر خلاف ویکیپدیا که سیاستهای شفاف درباره انواع منابع قابل قبول، سطوح استناد و نحوه حل اختلاف دارد، مدل مالکیت متمرکز گروکیپدیا (Grokipedia) باعث میشود مرز بین استناد علمی، برداشت تحلیلی مدل و حتی خلاصهسازی خلاقانه کمی مبهم شود. پژوهشهای اولیه درباره این پلتفرم نشان میدهد که بسیاری از مقالات، ترکیبی از چند منبع خبری و تحلیلی با وزندهی نامشخص هستند و کاربران امکان دیدن فهرست کامل منابع پشت صحنه را ندارند؛ دقیقا همان نقطهای که بحث منابع، استنادها و سوگیری در گراک پدیا حساس میشود.

مدل تولید محتوا، سوگیری الگوریتمی و پیامدهای آن
وقتی تولید محتوا به جای ویراستاران انسانی به دوش یک مدل زبانی بزرگ گذاشته میشود، شکل تازهای از سوگیری به وجود میآید که فقط با بررسی دقیق منابع، استنادها و سوگیری در گراک پدیا قابل تشخیص است. مدل «گروک» برای تولید پاسخ از دادههای وب، مجموعهای از خبرگزاریها، شبکههای اجتماعی و پایگاههای داده استفاده میکند و سپس این اطلاعات را در قالب یک مقاله ظاهرا منسجم ارائه میدهد. اما اگر دادههای ورودی خود دچار سوگیری سیاسی، جغرافیایی یا زبانی باشند، خروجی هم همین سوگیریها را به شکل پنهان بازتولید میکند.
منتقدان در شبکههای اجتماعی و تحلیلهای تخصصی درباره Grokipedia هشدار دادهاند که این سامانه به شدت در برابر «دستکاری سازمانیافته» آسیبپذیر است؛ یعنی اگر یک جریان رسانهای قدرتمند حجم زیادی محتوای همسو منتشر کند، مدل ممکن است آن را به عنوان روایت اصلی واقعیت بپذیرد و در مقالات بازتاب دهد. در چنین شرایطی، اگر راهکاری برای شفافسازی منابع، استنادها و سوگیری در گراک پدیا وجود نداشته باشد، کاربر نهایی متوجه نمیشود این دانش ظاهرا بیطرف بر پایه چه روایتهایی بنا شده است.
انواع سوگیری محتمل در مقالات گراک پدیا
با نگاهی تحلیلی به ساختار تولید محتوا میتوان چند نوع سوگیری را در چارچوب منابع، استنادها و سوگیری در گراک پدیا شناسایی کرد؛ برخی ناشی از دادههای آموزشی، برخی مربوط به انتخاب منابع زنده وب و بعضی دیگر مرتبط با اهداف تجاری و حاکمیتی پلتفرم هستند.
- سوگیری دادههای آموزشی: اگر دادههای اولیه که مدل بر اساس آن آموزش دیده بیشتر از رسانههای یک منطقه جغرافیایی یا گرایش سیاسی خاص آمده باشد، خروجی هم همان جهتگیری را تقویت میکند.
- سوگیری انتخاب منبع: الگوریتمهای جمعآوری داده ممکن است به رسانههای پربازدید یا همسو با معیارهای داخلی پلتفرم وزن بیشتری بدهند و در عمل صداهای حاشیهایتر یا اقلیتها کمتر دیده شوند.
- سوگیری حاکمیتی و تجاری: چون xAI یک شرکت انتفاعی است، تصمیمهای مربوط به انتشار یا عدم انتشار برخی موضوعها میتواند تحت تاثیر ریسک حقوقی، فشار سیاسی یا ملاحظات تجاری قرار بگیرد.
چگونه میتوان اعتبار منابع گراک پدیا را سنجید؟
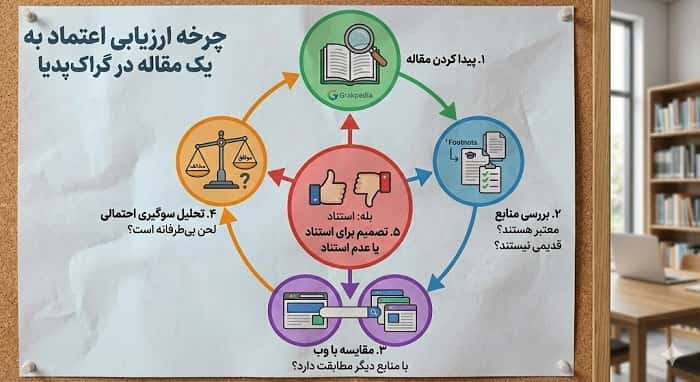
برای کاربری که در حال پژوهش، تولید محتوا یا طراحی استراتژی سئو است، مهمترین پرسش این است که با وجود چالشهای منابع، استنادها و سوگیری در گراک پدیا چگونه میتوان اعتبار هر صفحه را ارزیابی کرد. اولین گام این است که هیچگاه یک مقاله را منبع نهایی در نظر نگیرید و همیشه آن را با چند منبع مستقل دیگر مانند ژورنالهای علمی، گزارشهای رسمی یا پایگاههای داده معتبر مقایسه کنید.
گام دوم، توجه به الگوی استنادهای درون متنی است. اگر مقاله به طور مکرر به یک یا دو رسانه مشخص ارجاع میدهد، یا روایت آن با محتوای غالب وب درباره همان موضوع تفاوت شدید دارد، بهتر است آن را نشانهای از مشکل در منابع، استنادها و سوگیری در گراک پدیا در نظر بگیرید. در مقابل، وجود ارجاع به منابع متنوع، بینالمللی و علمی، احتمال سوگیری شدید را کاهش میدهد هرچند آن را از بین نمیبرد.
سومین گام، بررسی واکنش جامعه متخصصان و رسانهها به یک موضوع خاص است. در چند ماه گذشته گزارشهایی منتشر شده که نشان میدهد برخی سامانههای هوشمصنوعی هنگام پاسخگویی به پرسشهای حساس سیاسی یا تاریخی، به Grokipedia استناد کردهاند و همین موضوع بحث تازهای درباره مسئولیتپذیری و استانداردهای منابع، استنادها و سوگیری در گراک پدیا ایجاد کرده است.
رابطه منابع، استنادها و سوگیری در گراک پدیا با سئو و گراف دانش
از دید متخصصان سئو، منابع، استنادها و سوگیری در گراک پدیا فقط یک بحث نظری نیست، بلکه به طور مستقیم بر تصویر برندها در نتایج جستجو و حتی گراف دانش موتورهای جستجو اثر میگذارد. اگر یک مقاله درباره برند شما با استناد به منابع حاشیهای یا یکسویه نوشته شود و بعد همان مقاله توسط سامانههای دیگر به عنوان مرجع استفاده شود، یک چرخه تقویت سوگیری شکل میگیرد که اصلاح آن در آینده بسیار دشوار خواهد بود.
از سوی دیگر، اگر استراتژی شما این باشد که با تولید محتوای دقیق، شفاف و مبتنی بر منابع علمی در وب، غذای بهتری برای مدل فراهم کنید، میتوانید بخشی از منابع، استنادها و سوگیری در گراک پدیا را به نفع روایت صحیحتر درباره برند خود شکل دهید. این کار زمانی موثرتر است که در کنار حضور در این دانشنامه، ساختار دادههای سایت خود را با اسکیماهای سازمان، محصول و نویسنده تقویت کنید تا موتورهای جستجو بتوانند روایتهای مختلف را مقایسه و اعتبارسنجی کنند.
در نهایت، درک همزمان سازوکار سئو مبتنی بر Entity، گراف دانش و منابع، استنادها و سوگیری در گراک پدیا کمک میکند تصمیم بگیرید چه جاهایی بهتر است از این منبع نقل قول کنید و چه جاهایی باید به منابع کلاسیکتری مثل ژورنالهای داوریشده یا گزارشهای رسمی تکیه کنید. برای طراحی یک استراتژی کاملتر در این زمینه، مطالعه ((مقاله جامع گراک پدیا)) میتواند تصویر بزرگتری از جایگاه این دانشنامه در اکوسیستم جستجو به شما بدهد.

چالشهای شفافیت و مسئولیتپذیری در استفاده از گراک پدیا
یکی از مهمترین نقدهایی که پژوهشگران وب و اخلاق هوشمصنوعی به منابع، استنادها و سوگیری در گراک پدیا وارد میکنند، عدم شفافیت کامل درباره زنجیره تولید دانش است؛ کاربر به راحتی نمیتواند تشخیص دهد کدام جمله مستقیما از یک منبع بیرونی نقل شده، کدام بخش نتیجه استدلال مدل است و چه میزان ویرایش انسانی روی متن انجام شده است.
این ابهام زمانی جدیتر میشود که بدانیم حجم بزرگی از ترافیک آتی وب نه از سوی انسان، بلکه از سوی خود سامانههای هوشمصنوعی تولید خواهد شد؛ سامانههایی که ممکن است بدون کنترل کافی از همین مقالات به عنوان منبع استفاده کنند و در یک چرخه بسته، سوگیریها را تشدید کنند. به همین دلیل بسیاری از متخصصان پیشنهاد میکنند سازمانها در کنار رصد مداوم صفحه خود در این دانشنامه، سیاست داخلی مشخصی برای استناد به آن تدوین کنند و آن را در کنار منابع کلاسیکتری مثل ویکیپدیا و بانکهای اطلاعاتی علمی قرار دهند نه به جای آنها.
سخن آخر
در این مقاله تلاش کردیم نشان دهیم که موضوع منابع، استنادها و سوگیری در گراک پدیا فقط یک بحث تئوریک دانشگاهی نیست، بلکه به شکل مستقیم بر اعتماد کاربران، اعتبار علمی محتوا و حتی جایگاه برندها در نتایج جستجو اثر میگذارد. آشنایی با معماری این دانشنامه، مدل تولید محتوا و شیوه برخورد آن با منابع به شما کمک میکند هوشمندانهتر تصمیم بگیرید چه زمانی از آن نقل قول کنید و چه زمانی به سراغ منابع دیگر بروید.
اگر به عنوان مدیر بازاریابی، متخصص سئو یا تولیدکننده محتوا میخواهید از فرصتهای این پلتفرم استفاده کنید و در عین حال ریسکهای آن را کاهش دهید، لازم است همواره منابع، استنادها و سوگیری در گراک پدیا را با عینک انتقادی بررسی کنید، دادههای خود را در وب تقویت کنید و حضور برندتان را در این دانشنامه و سایر پایگاههای دانش به صورت مداوم رصد کنید. برای تکمیل این تصویر و شناخت دقیقتر جنبههای فنی و کاربردی، پیشنهاد میشود حتما ((مقاله جامع گراک پدیا)) را نیز مطالعه کنید تا استراتژی شما بر پایه درکی جامع از این اکوسیستم شکل بگیرد.
سوالات متداول درباره منابع و سوگیری گراک پدیا
گراک پدیا منابع خود را از کجا تامین میکند؟
گزارشها نشان میدهد این دانشنامه ترکیبی از دادههای وب، مقالات فورکشده از ویکیپدیا و متنهای تولیدشده توسط مدل «گروک» را به کار میگیرد و در برخی موارد از برچسبهایی مثل «Fact Checked by Grok» برای نشان دادن بازآزمایی بخشی از محتوا استفاده میکند.
آیا گراک پدیا نسبت به ویکیپدیا سوگیری کمتری دارد؟
مدل مالکیت و تولید محتوا در اینجا متمرکز و متکی بر هوشمصنوعی است، در حالی که ویکیپدیا بر مشارکت باز و فرآیندهای شفاف داوری تکیه میکند. پژوهشها تاکید میکنند که هر دو سامانه میتوانند سوگیری داشته باشند، اما شکل و منبع این سوگیریها متفاوت است و باید جداگانه تحلیل شود.
به عنوان پژوهشگر چگونه باید از مقالات گراک پدیا استفاده کنم؟
بهتر است آنها را نقطه شروع بدانید نه منبع نهایی. هر ادعای مهم را با چند مرجع مستقل مانند مقالات علمی، گزارشهای رسمی و پایگاههای داده تخصصی تطبیق دهید و هنگام نقل قول مستقیم، منبع اولیه را در استناد خود بیاورید نه تنها لینک به گراک پدیا.
آیا استفاده از گراک پدیا برای استناد در مقالات علمی مناسب است؟
در حال حاضر بسیاری از مجلات علمی استفاده مستقیم از دانشنامهها را به عنوان منبع اصلی توصیه نمیکنند، چه ویکیپدیا باشد چه گراک پدیا. بهتر است از این سامانه برای پیدا کردن سرنخ منابع اولیه استفاده کنید و در استناد رسمی، به همان مقالات و گزارشهای اولیه ارجاع دهید.
نقش گراک پدیا در تغذیه مدلهای هوشمصنوعی دیگر چیست؟
با توجه به این که برخی سامانههای هوشمصنوعی و حتی موتورهای جستجو شروع به استفاده آزمایشی از Grokipedia به عنوان یکی از منابع کردهاند، این دانشنامه میتواند بهطور غیرمستقیم بر پاسخهای بسیاری از ابزارهای هوشمصنوعی اثر بگذارد؛ موضوعی که حساسیت نسبت به کیفیت منابع و سوگیری را دوچندان میکند.
